DISeR: Designing Imaging Systems with Reinforcement Learning

Technical Video
Abstract
Imaging systems consist of cameras to encode visual information about the world and perception models to interpret this encoding. Cameras contain (1) illumination sources, (2) optical elements, and (3) sensors, while perception models use (4) algorithms. Directly searching over all combinations of these four building blocks to design an imaging system is challenging due to the size of the search space. Moreover, cameras and perception models are often designed independently, leading to sub-optimal task performance. In this paper, we formulate these four building blocks of imaging systems as a context-free grammar (CFG), which can be automatically searched over with a learned camera designer to jointly optimize the imaging system with task-specific perception models. By transforming the CFG to a state-action space, we then show how the camera designer can be implemented with reinforcement learning to intelligently search over the combinatorial space of possible imaging system configurations. We demonstrate our approach on two tasks, depth estimation and camera rig design for autonomous vehicles, showing that our method yields rigs that outperform industry-wide standards. We believe that our proposed approach is an important step towards automating imaging system design.
Paper

DISeR: Designing Imaging Systems with Reinforcement Learning
Tzofi Klinghoffer*, Kushagra Tiwary*, Nikhil Behari, Bhavya Agrawalla, Ramesh Raskar
Method
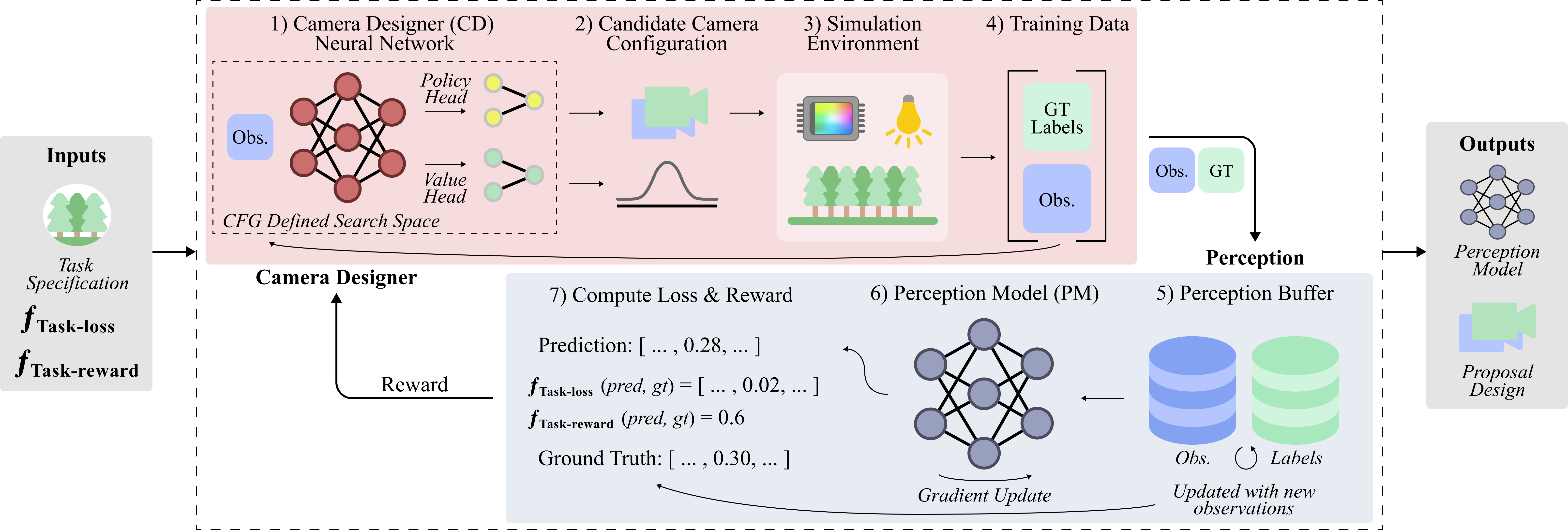
Our approach allows a camera configuration and perception model (PM) to be co-designed for task-specific imaging applications. At every step of the optimization, the camera designer (CD), implemented with reinforcement learning, proposes candidate camera configurations (1-2), which are used to capture observations and labels in a simulated environment (3-4). The observations and labels are added to the perception buffer (5) and used to compute the loss and reward, while the N most recent observations in the perception buffer are used to train the PM. The reward is propagated to the CD agent which proposes additional changes to the candidate camera configuration. After the episode terminates, the CD agent is trained using proximal policy optimization (PPO) until convergence.
Designing camera systems is non-trivial due to the vast number of engineering decisions to be made, including which parameters to use for illumination, optics, and sensors. We define a language for imaging system design using context-free grammar (CFG), which allows imaging systems to be represented as strings. The CFG serves as a search space for which search algorithms can then be used to automate imaging system design. We refer to such an algorithm as a camera designer (CD) and implement it with RL. RL allows us to search over imaging systems without relying on differentiable simulators and can scale to the combinatorially large search space of the CFG. Inspired by how animal eyes and brains are tightly integrated, our approach jointly trains the CD and PM, using the accuracy of the PM to inform how the CD is updated in training. Because searching over the entire CFG is infeasible with available simulators, we take the first step of validating that RL can be used to search over subsets of the CFG, including number of cameras, pose, field of view (FoV), and light intensity. First, we apply our method to depth estimation, demonstrating the viability of jointly learning imaging and perception. Next, we tackle the practical problem of designing a camera rig for AVs and show that our approach can create rigs that lead to higher perception accuracy than industry-standard rig designs.
Results
(Left) Camera rig designed with our approach, (Right) NuScenes camera rig
(Left) Images captured with camera rig designed with our approach, (Right) Images captured with NuScenes camera rig
We validate our approach with two tasks: (1) designing AV camera rigs for bird's eye view (BEV) segmentation, and (2) depth estimation.
AV Camera Rig Design: We apply our method to optimize an AV camera rig for the perception task of bird's eye view (BEV) segmentation by jointly training the camera designer (CD) and perception model (PM). The CD must choose both the number of cameras and the placement and FoV of each. The PM is trained with the output images from each candidate camera rig in simulated (CARLA) and its test accuracy (IoU) is used as the reward to update the CD. We find that the rigs created with our approach lead to higher BEV segmentation accuracy in our environment compared to the industry-standard nuScenes rig. The camera rig and resulting images of both our approach and nuScenes are visualized above. When tasked with designing AV camera rigs, the CD learns:
- Increase overlap between views: Increasing overlap between views allows objects to be visible in multiple images.
- Increase camera height: The CD learns to increase camera height, improving IoU of both occluded and unoccluded objects.
- Reduce camera pitch: The CD reduces camera pitch, in effect maximizing pixels on the road.
- Vary FoV: By varying the FoV among placed cameras, the CD may have learned a tradeoff between FoV and object resolution.
Depth Estimation: We validate our approach can learn the concept of stereo and multi-view depth estimation when monocular cues are unavailable. We train the CD and PM to estimate the depth of an object in an environment void of monocular cues. As a result, the CD learns to place multiple cameras, maximizing the baseline between each, to maximize depth estimation accuracy.
Citation
@inproceedings{tzofi2023diser,
author = {Klinghoffer, Tzofi and Tiwary, Kushagra and Behari, Nikhil and
Agrawalla, Bhavya and Raskar, Ramesh},
title = {DISeR: Designing Imaging Systems with Reinforcement Learning},
booktitle = {International Conference on Computer Vision},
year = {2023}
}
Acknowledgements
We thank Siddharth Somasundaram for his diligent proofreading of the paper. KT was supported by the SMART Contract IARPA Grant #2021-20111000004. We also thank Systems & Technology Research (STR).